|
import multiprocessing
|
|
import threading
|
|
import hashlib
|
|
import logging
|
|
import os
|
|
import sys
|
|
import time
|
|
|
|
from queue import Queue, Empty
|
|
from pathlib import Path
|
|
|
|
|
|
# Larger files are read by chunks.
|
|
CRITIC_SIZE = 100_000_000 # 100 MB.
|
|
# Larger files are ignored.
|
|
MAX_SIZE = 500_000_000 # 500 MB.
|
|
|
|
|
|
def get_file_id(file: Path, digest: str) -> str:
|
|
"""
|
|
Return the file ID for the specified file.
|
|
A file ID is composed by the file name, a separator
|
|
and the MD5 digest. Duplicate files will have the
|
|
same file ID.
|
|
"""
|
|
return f"{file.name}|{digest}"
|
|
|
|
|
|
def safe_print(print_lock: threading.Lock, *args: object) -> None:
|
|
"""
|
|
Like `print()`, but thread-safe.
|
|
"""
|
|
print_lock.acquire()
|
|
print(*args)
|
|
print_lock.release()
|
|
|
|
|
|
def get_file_md5(file: Path, size: int) -> str:
|
|
"""
|
|
Read the contents of the specified `file` and return
|
|
its MD5 digest.
|
|
"""
|
|
h = hashlib.md5()
|
|
split = size > CRITIC_SIZE
|
|
with file.open("rb") as f:
|
|
while True:
|
|
# If necessary, read by chunks.
|
|
chunk: bytes = f.read(CRITIC_SIZE if split else -1)
|
|
if chunk:
|
|
h.update(chunk)
|
|
else:
|
|
break
|
|
return h.hexdigest()
|
|
|
|
|
|
def worker(task_queue: Queue[Path],
|
|
print_lock: threading.Lock,
|
|
processed_files: list[tuple[Path, str]],
|
|
abort: threading.Event) -> None:
|
|
"""
|
|
Process files from the `task_queue` until the queue
|
|
is empty or the `abort` flag is set.
|
|
"""
|
|
while True:
|
|
try:
|
|
file = task_queue.get_nowait()
|
|
except Empty:
|
|
if abort.is_set():
|
|
break
|
|
else:
|
|
continue
|
|
process_file(file, processed_files, print_lock)
|
|
task_queue.task_done()
|
|
|
|
|
|
def process_file(file: Path,
|
|
processed_files: list[tuple[Path, str]],
|
|
print_lock: threading.Lock) -> None:
|
|
"""
|
|
Calculate the MD5 digest for the specified `file` and append
|
|
it to the `processed_files` list.
|
|
"""
|
|
size = file.stat().st_size
|
|
# Ignore large files.
|
|
if size > MAX_SIZE:
|
|
safe_print(print_lock, file, "omitted (too big).")
|
|
return
|
|
try:
|
|
hexdigest = get_file_md5(file, size)
|
|
except IOError as e:
|
|
logging.error("Could not read {file}: {e}")
|
|
else:
|
|
processed_files.append((file, hexdigest))
|
|
|
|
|
|
start_time: float = time.perf_counter()
|
|
logging.basicConfig(filename="duplicate_search.log", level=logging.DEBUG)
|
|
|
|
try:
|
|
# Where to start searching.
|
|
root = Path(sys.argv[1])
|
|
except IndexError:
|
|
print("Missing path.")
|
|
sys.exit()
|
|
|
|
if not root.exists():
|
|
print("Directory", root, "does not exist.")
|
|
sys.exit()
|
|
|
|
# List of processed files.
|
|
processed_files: list[tuple[Path, str]] = []
|
|
# A queue to communicate between workers.
|
|
task_queue: Queue[Path] = Queue()
|
|
# This lock ensures worker's prints do not overlap.
|
|
print_lock = threading.Lock()
|
|
cores = multiprocessing.cpu_count()
|
|
logging.info(f"{cores} CPU cores available.")
|
|
# List of workers.
|
|
threads: list[threading.Thread] = []
|
|
# When this event is fired workers will start returning.
|
|
abort = threading.Event()
|
|
|
|
# Spawn one worker per CPU core.
|
|
for _ in range(cores):
|
|
t: threading.Thread = threading.Thread(
|
|
target=worker,
|
|
args=(task_queue, print_lock, processed_files, abort)
|
|
)
|
|
t.start()
|
|
threads.append(t)
|
|
|
|
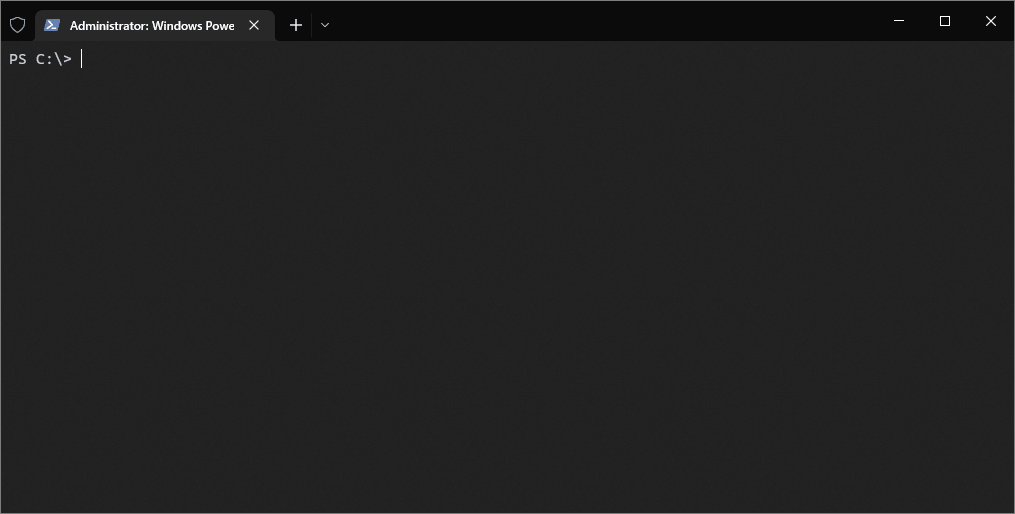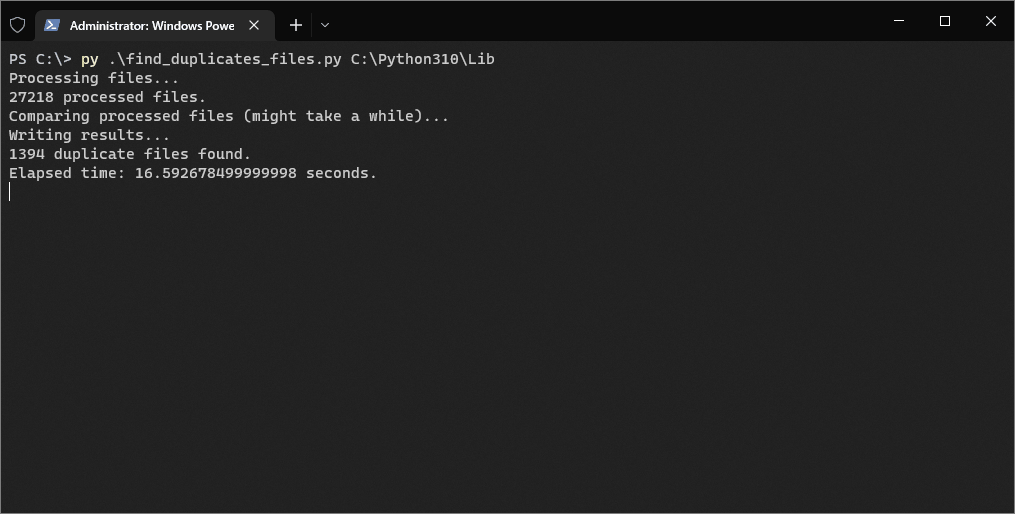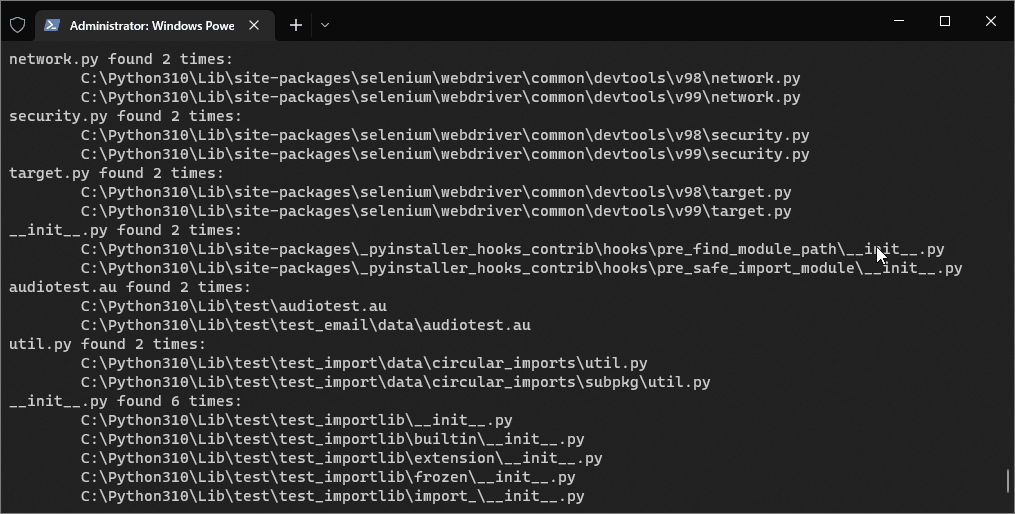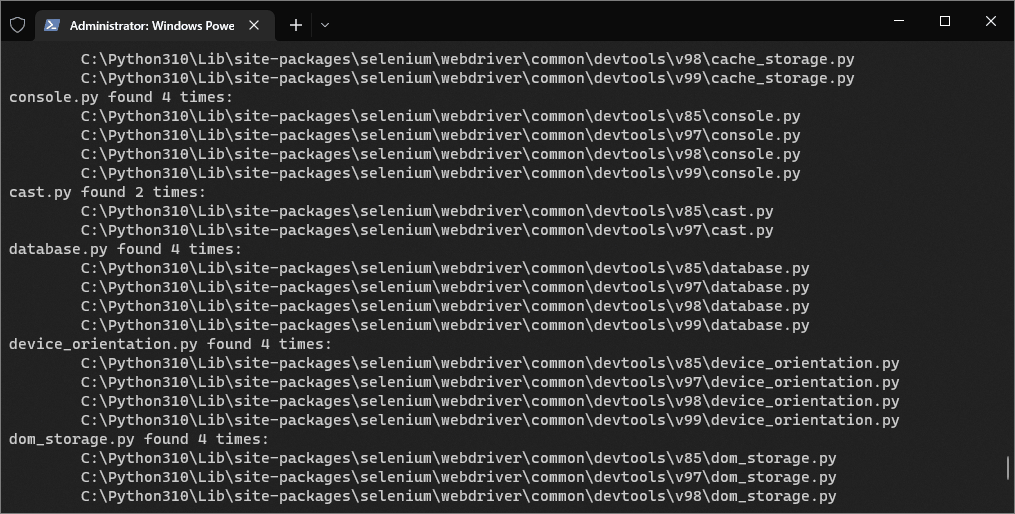
print("Processing files...")
|
|
try:
|
|
# Populate the queue with every file under
|
|
# the `root` directory (recursively).
|
|
for path, dirnames, filenames in os.walk(root):
|
|
for filename in filenames:
|
|
task_queue.put(Path(path, filename))
|
|
except KeyboardInterrupt:
|
|
logging.info("Manually stopped.")
|
|
|
|
# Tell the workers they need to return.
|
|
abort.set()
|
|
for t in threads:
|
|
t.join()
|
|
|
|
print(len(processed_files), "processed files.")
|
|
print("Comparing processed files (might take a while)...")
|
|
|
|
processed_files_ids: list[str] = [
|
|
get_file_id(file, digest)
|
|
for file, digest in processed_files
|
|
]
|
|
# The key is the file ID, the value is a list of
|
|
# paths containing every file with that ID within
|
|
# the `root` directory
|
|
duplicate_files: dict[str, list[Path]] = {}
|
|
|
|
for (file, _digest), file_id in zip(processed_files, processed_files_ids):
|
|
# Files with the same ID are duplicates.
|
|
matches: int = processed_files_ids.count(file_id)
|
|
if matches > 1:
|
|
files: list[Path]
|
|
try:
|
|
# Use the existing list of matches.
|
|
files = duplicate_files[file_id]
|
|
except KeyError:
|
|
# Create a new one if it's the first match.
|
|
duplicate_files[file_id] = files = []
|
|
files.append(file)
|
|
|
|
print("Writing results...")
|
|
with open("duplicate_files.txt", "w", encoding="utf8") as f:
|
|
for files in duplicate_files.values():
|
|
matches = len(files)
|
|
# Since `files` have duplicate files, then every file
|
|
# in the list has the same name. Just pick the first one.
|
|
f.write(f"{files[0].name} found {matches} times:\n")
|
|
# Write the full path of each duplicate file.
|
|
for file in files:
|
|
f.write(f"\t{file}\n")
|
|
|
|
print(len(duplicate_files), "duplicate files found.")
|
|
end_time: float = time.perf_counter()
|
|
print("Elapsed time:", end_time - start_time, "seconds.")
|